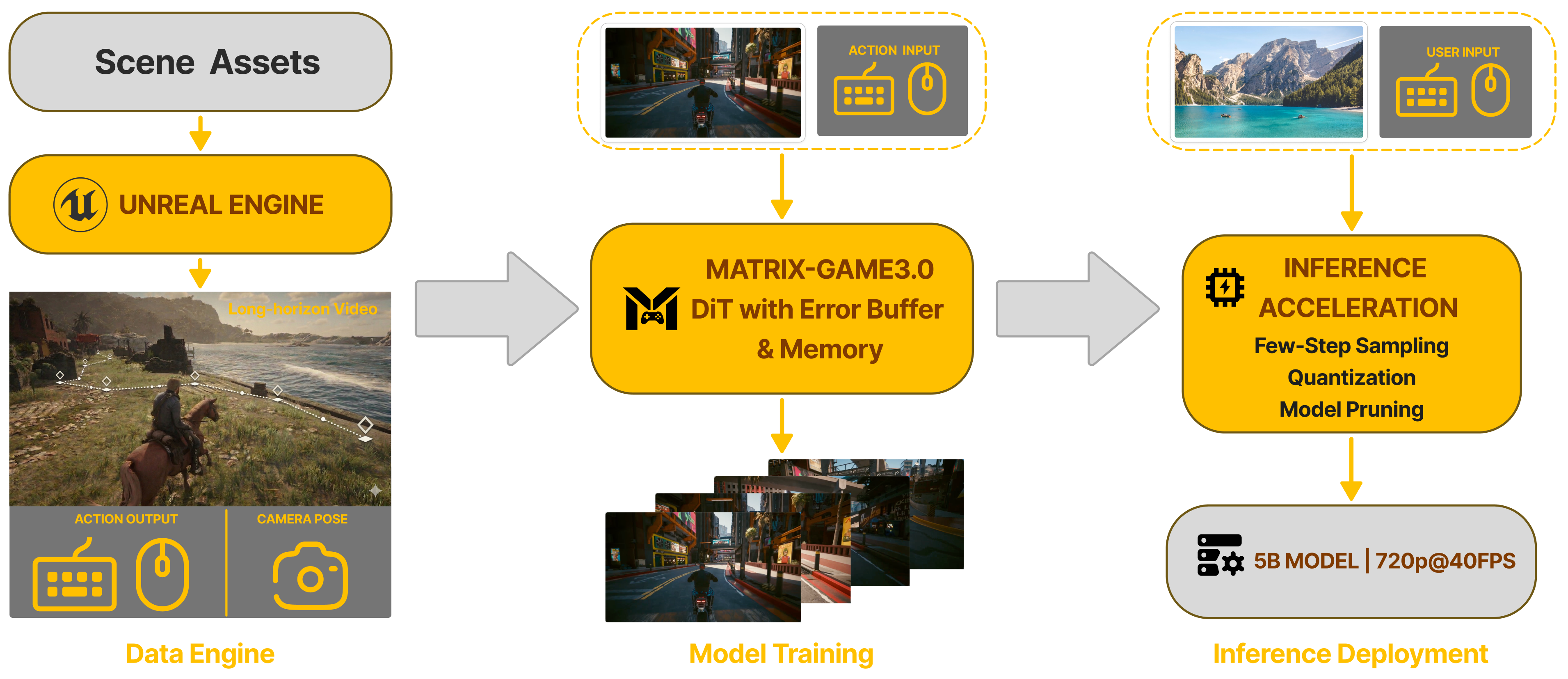
Method Overview
Our framework unifies three stages into an end-to-end pipeline: (1) Data Engine — an industrial-scale infinite data engine integrating Unreal Engine synthetic scenes, large-scale automated AAA game collection, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplets at scale; (2) Model Training — a memory-augmented Diffusion Transformer (DiT) with an error buffer that learns action-conditioned generation with memory-enhanced long-horizon consistency; (3) Inference Deployment — few-step sampling, INT8 quantization, and model distillation achieving 720p@40FPS real-time generation with a 5B model.
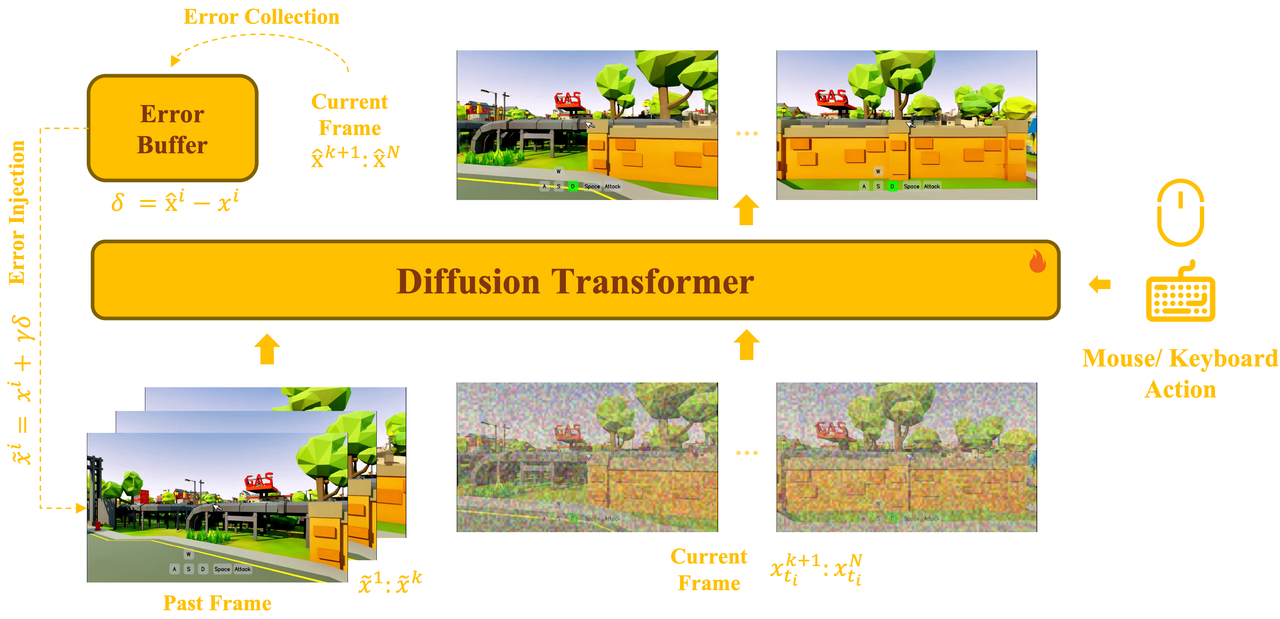
Error-Aware Interactive Base Model
The base model uses a unified bidirectional Diffusion Transformer that jointly models past latent frames, noised current frames, and action conditions (mouse/keyboard) within a single architecture. During training, an error collection mechanism records prediction residuals δ = x̂ᵢ − xⁱ into an error buffer, while error injection x̃ᵢ = xⁱ + γδ introduces controlled perturbations to simulate imperfect conditioning. This bridges the gap between clean-data training and noisy autoregressive inference, enabling the model to learn self-correction over long-horizon rollouts.
Memory-Augmented Generation
Built upon the base model, retrieved memory frames are incorporated as additional conditions via a joint self-attention mechanism. Memory latents, past frame latents, and noised current frame latents are placed into the same attention space, enabling the model to jointly attend to long-term memory, short-term history, and the current prediction target within a single denoising hierarchy.
Camera-aware memory selection retrieves only view-relevant historical content based on camera pose and field-of-view overlap, accompanied by relative Plücker encoding for cross-view geometric representation. A persistent sink latent (the first frame) serves as a global anchor for scene style and appearance. Small memory perturbations further enhance robustness during inference.

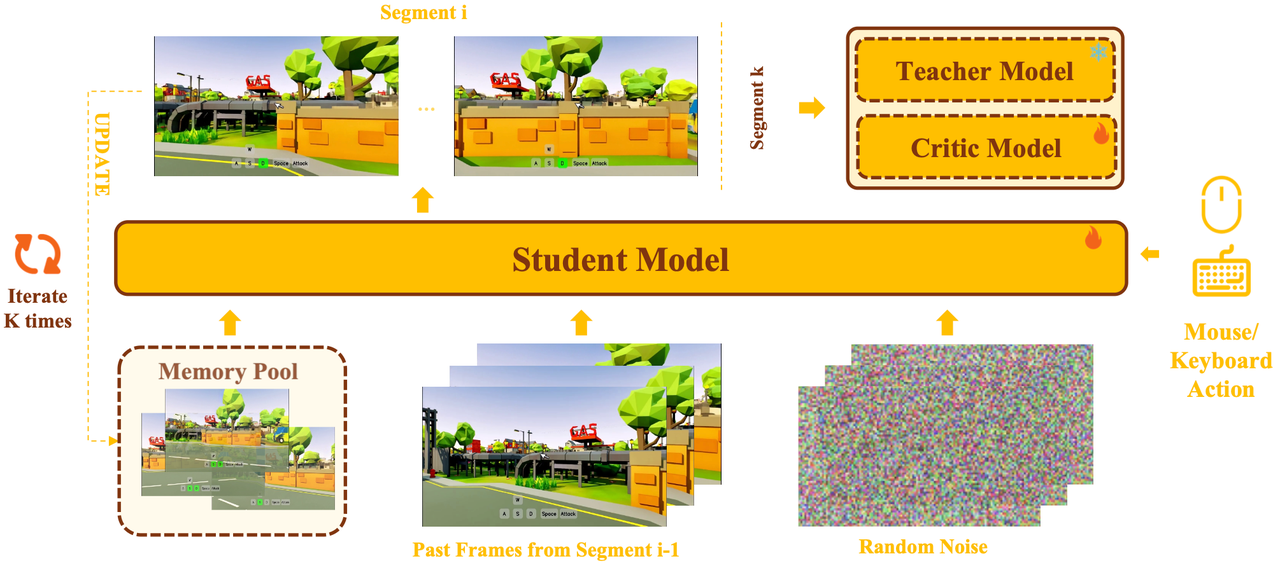
Training–Inference Aligned Few-Step Distillation
We introduce a multi-segment self-generated inference scheme for the bidirectional student, based on Distribution Matching Distillation (DMD). The student performs multi-segment rollouts that mimic actual few-step inference: each segment starts from random noise, with past frames taken from the tail of the previous segment and memory retrieved from an online-updated memory pool. The final segment is used for distribution matching, thereby ensuring training–inference consistency.
Combined with INT8 quantization for DiT attention layers, a lightweight pruned VAE decoder (MG-LightVAE, up to 5.2× speedup), and GPU-based camera-aware memory retrieval, the full pipeline achieves up to 40 FPS real-time generation at 720p resolution using 8 GPUs for DiT inference and 1 GPU for VAE decoding.